Как устроена Единая биометрическая система
Автор Сергей Браун
Дата публикации: 8 сентября 2021
Блог компании Конференции Олега Бунина (Онтико), Блог компании Команда Госуслуг
Анализ и проектирование систем * Apache * Hadoop *
Единая биометрическая система (ЕБС) с 2018 года используется для идентификации человека по его биометрическим характеристикам: голосу и лицу.
Чтобы получать услуги по биометрии, пользователю необходимо зарегистрироваться в системе в одном из 13,1 тысяч отделений банков. Там операционист сделает его фотографию, запишет голос и отправит эти данные в систему. А для того чтобы компании могли оказывать по биометрии различные услуги, им необходимо провести интеграцию с ЕБС.
Оператором системы является «Ростелеком», а разработкой занимаемся мы – дочерняя компания РТЛабс .
Меня зовут Сергей Браун, я заместитель директора департамента цифровой идентичности в РТЛабс. Вместе с Артуром Душелюбовым, начальником отдела развития и разработки департамента цифровой идентичности, мы расскажем, как мы создавали платформу для любой биометрии, с какими проблемами встретились и как их решали.

Для тех, кто предпочитает видео – смотрите выступление на HighLoad++ Весна 2021, под катом ждет запись.
Биометрия. Начало

Когда наше государство решило сделать биометрическую систему, первый вопрос, который возник у нас: «Хорошо, но как это организовать?». Мы не хотели изобретать велосипед и знали, что очень много коллег работают с самой разной биометрией. Поэтому сначала мы посмотрели, что есть на рынке. Оказалось, что существует много решений вендоров, а модные сегодня нейросети постоянно развиваются, обучаются и растут. Здорово!
Мы стали изучать существующие решения и выяснили, что у каждого вендора свои характеристики биопроцессоров. Один работает лучше, другой — хуже. Этот видит в темноте, а тот — нет, кто-то умеет распознавать голос. А нам нужен был однозначный результат. В итоге мы решили проверять вендоров по нескольким модальностям с несколькими сетями и работать с разными вендорами, чтобы брать от каждого лучшее.
С другой стороны, перед нами стояли вопросы безопасности. Когда к нам приходит человек, для платформы он находится в удаленном канале, мы его не видим. Нам неизвестно, что происходит с ним, где он, как он выглядит. Но нам надо понимать, что это действительно человек, а не фото или видеозапись, смонтированная злоумышленниками. И уметь отражать возможные атаки.
И, конечно, бизнес хотел знать, сколько будет ему стоить риск ошибки распознавания биометрии. Не говоря уже о том, что вся система должна работать отказоустойчиво, без потерь данных и не разъехаться под нагрузкой.
Итак, что в итоге у нас получилось.
Нейросети и попугаи
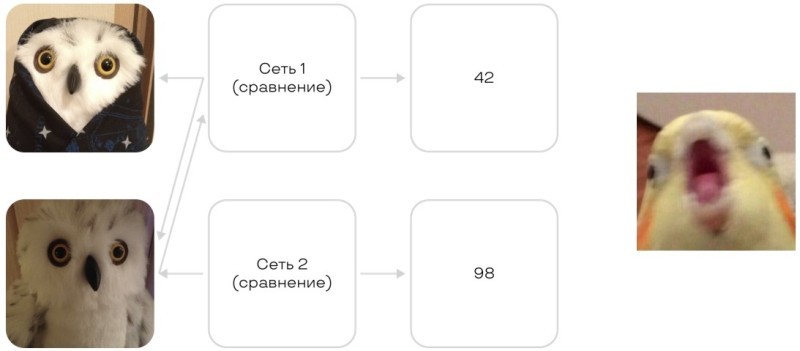
Нейросети работают загадочно. Если попросить вендоров сравнить две фотографии, то мы получим разные score. Один вендор скажет 42, другой — 78, а третий — 33. Почему так? И что это означает?
Чтобы понять их объяснения, нам пришлось собрать собственную базу образцов и на ней измерять самим:
-
Вероятность ложного допуска;
-
Вероятность ложного недопуска;
-
Вероятности ложного совпадения;
-
Вероятности ложного несовпадения;
-
Обобщенную вероятность ложного допуска;
-
Обобщенную вероятность ложного недопуска.
Мы открыли ГОСТ, написали много кода и посчитали реальные вероятности для каждого score каждого вендора.
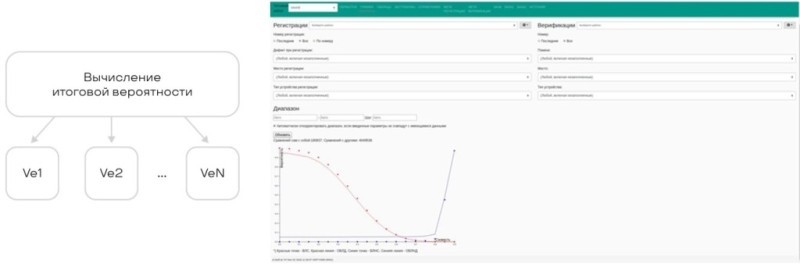
И теперь, когда вендор скажет 42, мы его поймем. Потому что увидим, что 42 у этого вендора — это хорошая история, там точность 10-7, ошибка второго рода. Можно пользоваться.
Так мы закрыли первый шаг нашей схемы ЕБС:
Сравниваем биометрию
На следующем этапе мы создали отдельные процессы переиндексации данных и перерегистрации образцов во всех биометрических процессорах. Потому что вендоры постоянно что-то меняют в своих нейросетях. У каждого своя платформа, и не все извлекают шаблон по запросу. Плюс у всех различное API.
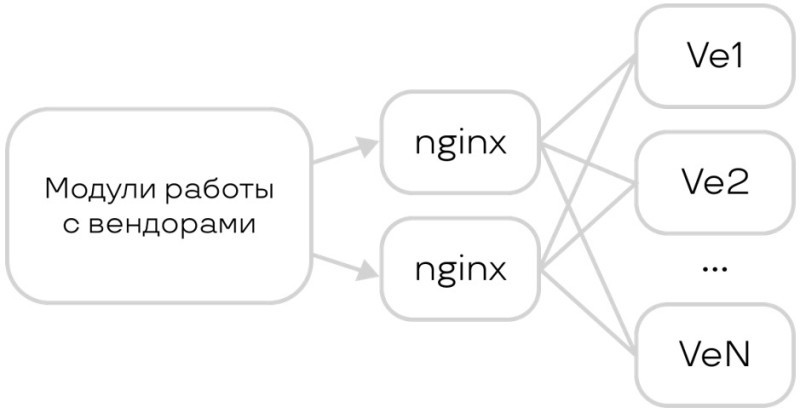
С API мы решили просто. Предложили вендорам реализовать стандартную и очень простую API, всего из пары методов. Это стало необходимым условием сотрудничества. Многие смогли это сделать.
Сейчас процесс выглядит примерно так. Для нас вендор — это black box, перед которым мы ставим nginx для балансировки. Если вендор медленный, то для распределения нагрузки мы ставим его 10-20 копий. Когда нам надо сравнить две фотографии, мы отправляем их вендору в разные API: «Вот два вектора, они похожи или нет?»
Что происходит, когда к нам приходит биометрия, например, фотография? Мы распознаем, что это она, а затем смотрим в конфиг, сколько у нас вендоров. Например, шесть. У каждого из них мы запрашиваем на фотографию вектор, он же шаблон. К сожалению, вендор отвечает не всегда, потому что не все из них извлекают данные. Но в итоге фотографию и все векторы (биометрические шаблоны), которые вендор смог из нее извлечь мы сохраняем к себе.
Сейчас, когда к нам приходит новый вендор, все наши актуальные фотографии сразу проходят через него. То же самое мы делаем и со звуком, и с чем угодно.
Так мы закрыли следующий квадрат схемы:

Как обезопасить себя и клиента?
На рынке много решений для проверки, что это живой человек, а не фотография или видео. Разница в том, что одни хорошо видят подделки на веб-камере, а другие — на фотографиях, снятых телефоном. Еще можно проверять не по фотографии, а по голосу. Третий вариант — взять видео и проверять и по голосу, и по лицу. Посмотреть, как человек открывает рот, правильные ли буквы говорит, хорошо ли их произносит, и вообще не монтаж ли это.
Мы решили комбинировать всё, чтобы наверняка удостовериться, что человек живой. Подход применяем такой же, как на предыдущем шаге. Считаем liveness обычным вендорским решением с единой API. Если интересно, на портале можно об этом прочитать подробнее.
Так мы закрыли очередной элемент нашей схемы ЕБС:
Транспорт и очередь
После того, как работа с вендорами наладилась, мы стали смотреть, что за биометрия к нам приезжает.
Например, мы хотим проверить человека, который открывает счет. Операция не самая простая, поэтому хочется надежно проверить, что это действительно он. Мы запрашиваем данные в виде видео, потому что это пока самый надежный liveness.
Такое видео весит ~20Mb на транзакцию. По-хорошему, нам нужно транспортировать и фотографию, а качественная фотография легко может весить 1Mb. А еще некоторые вендоры возвращают нам на 30Kb звука мегабайтный вектор. Чтобы передвигать это всё по системе, мы выбрали отличное решение, о котором наверняка все знают.
Очереди c персистентностью + балансировка
Мы взяли Kafka, потому что она довольно простая и эффективная для решения задач с большим количеством мегабайтов. Создали очереди, поставили модули с двух сторон: один пишет, второй читает. С каждой стороны их, очевидно, может быть несколько:

При всей своей простоте Kafka децентрализована. Это позволило нам малой кровью закрыть возможности масштабирования и вопросы балансировки. Стандартные механизмы балансировки Kafka позволяют читателям отваливаться, приходить и уходить.
С точки зрения надежности Kafka позволяет получить копии упавшего модуля и все данные с него. Даже если упала вся нода или весь сервер. Если потребитель не обработал сообщение, он для Kafka его не коммитит. Даже если модуль «умрет», то другая копия получит данные и выполнит задачу.
Очереди с репликацией
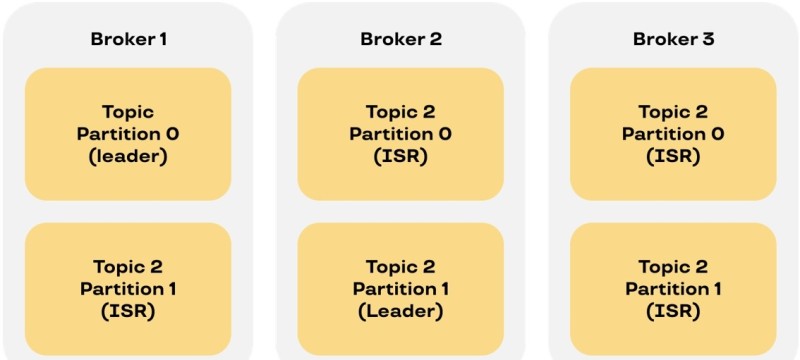
Поскольку Kafka живет в основном на дисках, то по факту это — журнал. Поэтому мы осознанно пошли на то, что, если данные отреплицировались, то мы ждем при записи с каждого из наших модулей ответ от всех имеющихся в кластере брокеров. И так как в этом случае нам быстрые и дорогие диски не нужны, мы взяли обычные. Репликация позволяет их легко менять если что-то выйдет из строя чисто механически или совсем невосстановимо по софту.
А так как Kafka поделена внутри себя на партиции, то, если одна выпадет, мы сможем прожить какое-то время на оставшихся. И одновременно за счет количества партиций мы увеличиваем потенциально возможное количество читателей.
Сравнение с RMQ
Вполне логичный вопрос — почему именно Kafka? А не, например, тот же RabbitMQ?
Первая и основная причина — это децентрализация. У RabbitMQ есть Central Store. Да, он имеет свои механизмы отказоустойчивости. Но он не предназначен для того, чтобы в него передавать ощутимый объем сообщений, при этом еще и разный, скачущий то вверх, то вниз. Не очень понятно, как он себя будет вести. Плюс у него довольно плотная связь с памятью.
У других решений такого же типа механизм чтения и общения с очередями построен так, что если потребитель забрал то, что отправили, это считается доставленным. В Kafka, в силу того, что она ближе к журналу, сообщение будет храниться вне зависимости от того, прочитал его потребитель или нет. Сообщение будет удалено только в момент срабатывания определенной политики очистки по месту или по времени.
Нам не очень хотелось устраивать сложную маршрутизацию и строить хитрые схемы. Проще записать один раз — кому надо, те придут и прочитают. Всю архитектуру системы мы построили в основном в режиме пайплайнов, то есть это прямой поток, когда от очереди не нужен роутинг.
Но в случаях, когда он нам все-таки нужен, Kafka тоже справилась.
Схема с Kafka streams для конвейеров обработки
Мы просто воспользовались встроенной логикой самой Kafka, ее удобным DSL с возможностью за счет механизмов кеш-журналов переобработать сообщение, если что-то пошло не так. Мы поставили один модуль с Kafka-стримами и сагрегировали то, что нужно:
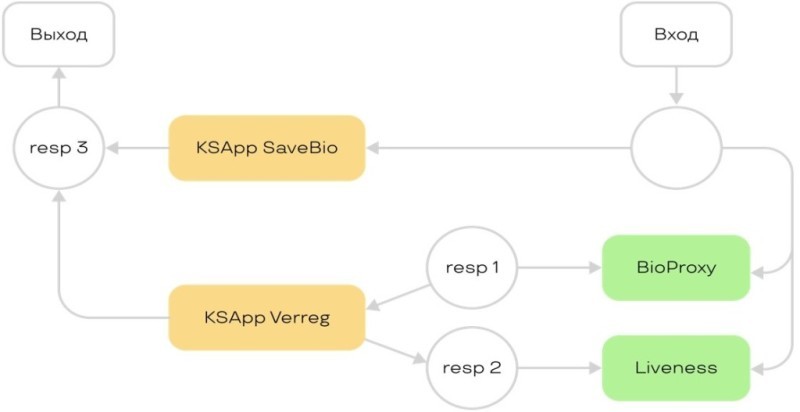
Здесь логика такая. Если к нам на вход что-то пришло, мы разветвляем работу и собираем воедино, дожидаясь результата. Например, на схеме видно, что мы работаем параллельно с несколькими вендорами и с liveness. В этом режиме нам помогают именно стримы.
Так мы достроили еще один элемент нашей архитектуры:
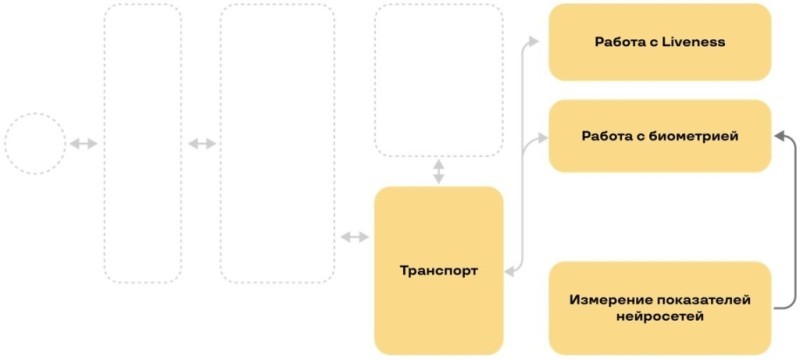
Передавать научились – давайте сохраним!
Логика RegionServer’а
Когда мы посмотрели на данные, которые у нас ходят, то увидели, что они все неструктурированные и вообще непонятные. Для странного и непонятного мы нашли отличное решение — HBase поверх Hadoop.
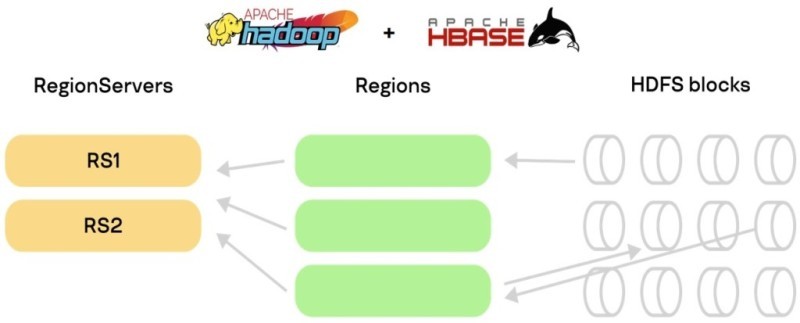
В силу того, что HBase — это колумнарная база данных, выросшая из BigTable, в ней есть ряд особенностей того, как она хранится на дисках в самом «низу» схемы хранения. Так как там есть прямой стык с HDFS, то она может жить на распределенной FS (файловой системе).
В HBase также есть понятия RegionServer и Region, которые по факту — единицы хранения. И мало того, что они хранятся обособленными кусками, так каждый из них может распределяться на блоки HDFS. Далее эти блоки разделяются на файлы в обычной FS на диски на машинах. Что опять нас возвращает к тому, что есть много дешевых дисков. Почему бы не использовать их примерно для того же, что и в Kafka? И этот подход себя оправдал.
Логика сбора данных выглядит так. RegionServer отвечает за Region, он управляет одним или несколькими регионами. Дальше все это проваливается в HDFS. Здесь применяется фактор репликации, который вы настроили. Потерять что-нибудь очень трудно.
Посмотрим, как это стыкуется с тем, что мы говорили про передачу биометрии и прогон сообщений с биометрией по Kafka.
Распределение нагрузки на кластер
Здесь все довольно просто. У нас есть некие однотипные данные с точки зрения того, как они выглядят. Но они могут быть размером как 10Mb и больше, так и 1Kb. Логично разделить их по какому-то признаку, чтобы не перемешивать и равномерно сложить.
Для этого мы взяли таблицы HBase, так как там есть понятие column family. По факту это просто объединение данных, которое уже внизу разделяется на регионы. И при этом все хранится единым куском.
Мы разделили один column family — одна модальность. Это может быть либо отдельно звук, либо голос, либо еще что-нибудь. Но если мы поставим, например, размер региона 10Gb, то не будем умирать на постоянных compaction или на сложных перебалансировках таблиц.
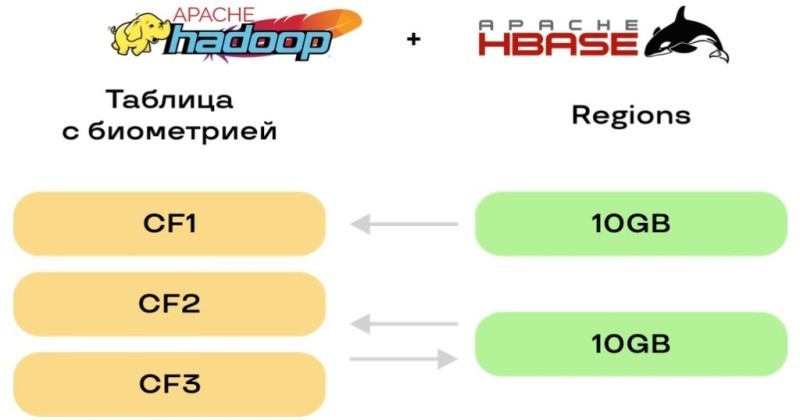
Конечно, стандартная рекомендация HBase по настройкам — делать регионы поменьше. Потому что, когда в HBase что-то пишется, весь column family начинает схлопываться и собираться или, наоборот, разбиваться. Это одна из самых тяжёлых операций для HBase, которая использует память по количеству объектов. Но, так как у нас регионы хоть и достаточно крупные, но их немного, то мы можем себе это позволить. Плюс это равномерным слоем ляжет в FS, распределившись на диски и на машины.
Что в итоге получилось?
Схема хранения биометрии по CF + запросы
По логике получаемых данных мы их разделили на модальности: фото, звук, видео. Вендоры отдают нам шаблоны разного размера и объёма, с разными характеристиками. Мы их также поделили на column family и назначили каждому вендору свой.
Каким образом это все раскладывать так, чтобы не делать bottleneck, не пережать при перебалансировке? Здесь у нас подход довольно стандартный. В HBase все привязано к row key. Чем лучше вы определили, какие ключи будут использоваться в качестве ключей для строк, тем равномернее можно распределить данные.
Например, можно взять Round Robin, сделать пресплит таблицы, и начать «проворачивать» ключи (row key) так, чтобы они не шли непосредственно инкрементально друг за другом (+1). Обеспечить такое распределение можно просто меняя первый и последний байт ключа. Мы так и сделали. Начинаем отсчёт с нуля, дальше просто меняем байты и получаем цифры уже не от 0 до N, а инкремент по несколько другой логике.
Это позволяет наполнять довольно равномерно каждый из RegionServer, распределяя при этом нагрузку, в том числе и на запись, на разные машины, диски и ноды в самом кластере.
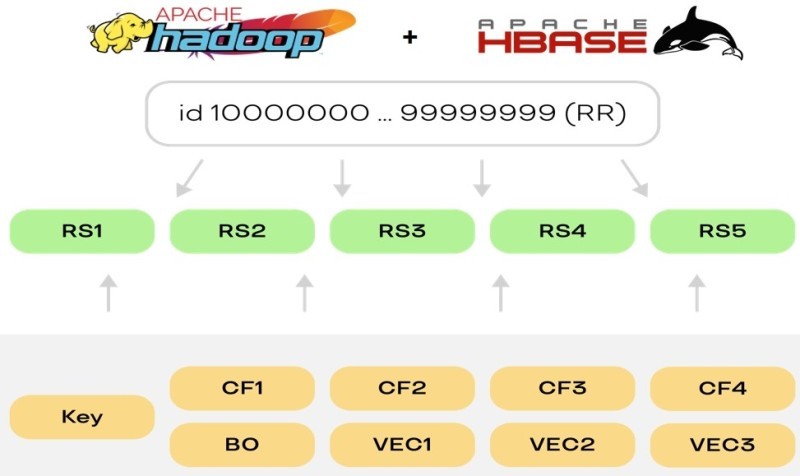
Дело в том, что HBase набивает каждый регион по кускам. Он просто назначает каждому региону диапазон id. Если вы будете инкрементально крутить id каким-нибудь автоинкриментом, вы положите всю запись в один RegionServer. HBase будет «греть» одни и те же диски, и в какой-то момент они рассплитятся. Для нас стало лучшим решением простая замена двух байтов местами в инкрементальном id.
А мы тем временем донесли данные и сложили на хранение:
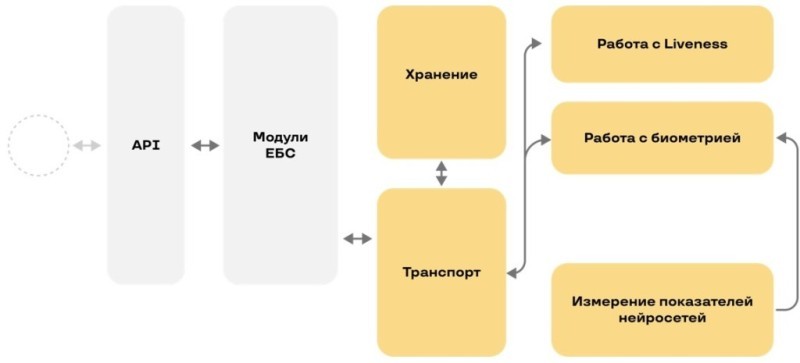
Мультимодальность, мульти-liveness
Теперь надо поговорить о том, как это работает. У нас есть Kafka и модули, которые работают сами по себе:

Когда человек хочет пройти биометрическую верификацию, фронт запрашивает одноразовые инструкции персонально под этого человека, сгенерированные прямо сейчас. Он получает их из модуля инструкций (который, кстати, тоже пишет всю историю в тот же самый HBase) и отвечает наружу.
Человек выполняет инструкции, например, улыбается или приседает — всё, что мы его просим сделать. Потом присылает нам видео, и мы начинаем его разбирать. Вытаскиваем фотографию, отрезаем звук. Если проверок несколько, то определяем, какой liveness какую часть будет проверять. Все раздаем по исполнительным модулям. После этого получаем результат, собираем его и отдаем наружу. Вроде бы всё понятно. Но для нас возникает следующая проблема.
Модулей у нас много. И каждый должен быть запущен не в одном экземпляре, а нескольких. Если API не один, а хотя бы два, то запрос пришел на одну ноду, а ответ может получить другая. А нам надо ответить точно в тот же TCP-коннект. Что делать?
Мы нашли простое решение. У Redis есть хороший механизм PubSub, и мы отправляем ему все пакеты с id. Когда какая-то из нод получает ответ, она проверяет — это мой коннект или нет? Если это не ее коннект, она отдает данные в Redis. Та нода, которая изначально получила запрос, на эту информацию подписана. При изменении данных в Redis через механизм PubSub она всё получает и может отвечать наружу.
В качестве приятного бонуса мы решили с помощью Redis также оповещать модули. Мы просто подписываемся на нужный ключ в Redis. Когда произойдет ивент того, что админ что-то настроил, модулю не надо ничего перезапускать. Он получит этот ивент через Redis, заберет нужное обновление из реестра, и проапдейтится.
Вторым приятным бонусом для нас стал отказ от Zookeeper. С ним мы жили вполне успешно, пока модулей было не очень много и не было постоянного изменения сторонних настроек для модулей (например, настроек вендоров или модальностей). Балансировка была построена на том, что Zookeeper и Kafka всё между собой синхронизировали.
Но как только появились настройки, отличающиеся от технических настроек модулей, возникла проблема. Человеку, который видит Zookeeper второй и даже третий раз, довольно сложно посмотреть, что в нем хранится. Приходилось все время вспоминать, как работать с Zookeeper.
В итоге мы выпилили много кода взаимодействия с Zookeeper, синхронизации, подключения и уменьшили объём конфигов. Переехали в обычные плоские JSON-конфиги. Выкатили модуль в OpenShift, дали ему новый configmap, он при подъеме с контейнера получил JSON, и всё работает. Всем стало проще.
Мы пришли почти к финалу. Осталось поговорить про внешние API.

Внешнее взаимодействие
Мы не находимся внутри бункера. У нас есть еще потребители сервисов, и им надо как-то помочь. Если для наших сложных проверок просто написать им текстовые инструкции, то это не сработает. Поэтому мы сами реализовываем логику инструкций и проверки на стороне платформы.
У нас есть своя часть фронта, у клиента — своя. Например, для телефона это SDK. Но лучше сделать всё через наше приложение, которое само реализует эту сложную логику.
Преимущество в том, что мы полностью контролируем фронт. А значит, если нас ломают или нам надо срочно внедрить новые liveness или проверки, мы проводим эти работы сами. Не ждем, пока контрагент встроит в свое приложение нашу новую версию.
Протокол у нас общий и на веб-интерфейсе, и на мобильной версии — мы видим, кто пользуется сервисом. И в зависимости от того, какие сигналы пришли, например, от системы аномалий, мы можем сформировать инструкции для этой конкретной сессии, для конкретного человека.
Например, если пользователь всегда приходил с одного телефона, мы проводим обычную проверку. Если человек поменял локацию или устройство для входа, то это подозрительно. Да, может быть неудобно проходить дополнительные проверки, но зато ваши деньги надежно защищены - их вместо вас никто не снимет.
Наружу мы отдаем всего пару простых интерфейсов. Тем самым мы закрываем проблемы с нормативами и сертификацией.
Финальные штрихи.
Итак, мы сложили полную схему ЕБС:
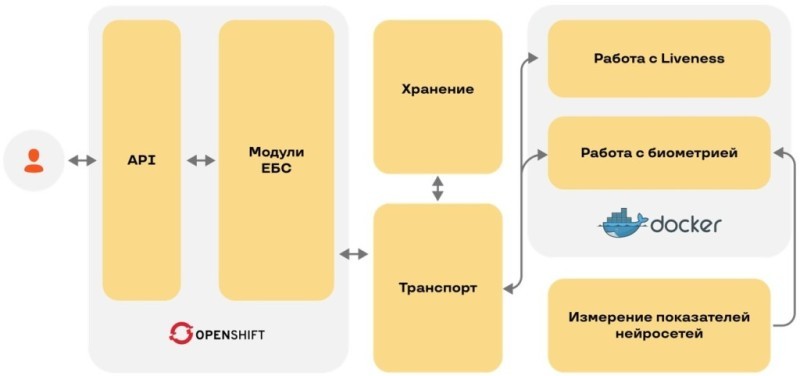
Остается сказать несколько слов об архитектуре.
Мы используем Docker, который прекрасно работает для биометрических вендоров, потому что они используют библиотеки, собрать которые самому невозможно. Для себя мы от всех вендоров запрашиваем докер-образ.
А дальше мы ставим кластер Hadoop, транспорт в Kafka, хранение в HBase. Hadoop — хорошая база данных, а все остальные модули размещаем в OpenShift.
Вот так сложилась архитектура Единой биометрической системы.
Иллюстрации: Михаил Голев
Видео нашего выступления можно посмотреть здесь.